크라우드 소싱 정렬로 백만 개의 이미지 순위를 매기는 방법
사람들이 가장 매력적으로 생각하는 이미지를 찾기 위해 사이트 방문자가 평가할 수있는 게임을 만들어 풍경 이미지 모음의 순위를 매기고 싶습니다.
그렇게하는 좋은 방법은 무엇입니까?
- Hot-or-Not 스타일 ? 즉, 단일 이미지를 표시하고 사용자에게 1-10의 순위를 지정하도록 요청합니다. 보시다시피, 이것은 점수를 평균화 할 수있게 해주 며, 모든 이미지에 대해 균등 한 투표 분포를 얻도록해야합니다. 구현이 매우 간단합니다.
- A- 또는 -B를 선택 하시겠습니까? 즉, 두 개의 이미지를 표시하고 사용자에게 더 좋은 이미지를 선택하도록 요청합니다. 숫자 순위가 없기 때문에 매력적입니다. 단지 비교 일뿐입니다. 하지만 어떻게 구현할까요? 내 첫 번째 생각은 인간이 비교 작업을 제공하는 빠른 정렬로 수행하고 완료되면 단순히 정렬 ad-infinitum을 반복하는 것입니다.
어떻게 것입니다 당신이 그것을 할?
숫자가 필요하다면 매일 20,000 회 방문하는 사이트에서 백만 개의 이미지에 대해 이야기하고 있습니다. 나는 논쟁을 위해 작은 비율이 게임을 할 것이라고 상상하고, 하루에 2,000 개의 인간 정렬 작업을 생성 할 수 있다고 가정하자! 비영리 웹 사이트이며, 호기심이 많은 사람들은 내 프로필을 통해 찾을 수 있습니다. :)
다른 사람들이 말했듯이 1-10 순위는 사람들의 수준이 다르기 때문에 잘 작동하지 않습니다.
Pick A-or-B 방법 의 문제점 은 시스템이 전 이적이라는 보장이 없다는 것입니다 (A는 B를 이길 수 있지만 B는 C를, C는 A를 이깁니다). 비전 이적 비교 연산자가 있으면 정렬 알고리즘이 손상됩니다 . 이 예에서 퀵 정렬을 사용하면 피벗으로 선택되지 않은 문자가 서로에 대해 잘못 순위가 지정됩니다.
주어진 시간에 모든 사진의 절대 순위를 원합니다 (일부 / 모든 사진이 동률이더라도). 또한 누군가 투표하지 않는 한 순위가 변경 되지 않도록합니다 .
내가 사용하는 것이 피킹 A-또는-B (또는 타이) 방법을하지만, 유사 순위를 결정하는 일로 평가 시스템 이 개 플레이어 게임 (원래 체스)에서 순위에 사용됩니다 :
Elo 플레이어 등급 시스템은 플레이어의 경기 기록을 상대방의 경기 기록과 비교하고 플레이어가 경기에서 승리 할 확률을 결정합니다. 이 확률 계수는 각 경기의 결과에 따라 플레이어의 등급이 올라가거나 내려가는 점수를 결정합니다. 플레이어가 더 높은 등급의 상대를 이길 때 플레이어의 등급은 더 낮은 등급의 플레이어를 이겼을 때보 다 더 높아집니다 (플레이어는 더 낮은 등급의 상대를 이겨야하기 때문입니다).
Elo 시스템 :
- 모든 신규 플레이어는 기본 등급 1600으로 시작합니다.
- WinProbability = 1 / (10 ^ ((상대의 현재 등급 – 플레이어의 현재 등급) / 400) + 1)
- ScoringPt = 경기에서 이기면 1 점, 패하면 0 점, 무승부에서는 0.5 점.
- 플레이어의 새 등급 = 플레이어의 이전 등급 + (K- 값 * (점수 점수 – 플레이어의 승 확률))
"플레이어"를 그림으로 바꾸면 공식에 따라 두 그림의 등급을 간단하게 조정할 수 있습니다. 그런 다음 해당 숫자 점수를 사용하여 순위를 지정할 수 있습니다. (여기서 K-Value는 토너먼트의 "레벨"입니다. 소규모 지역 토너먼트의 경우 8-16이고 대규모 초대 / 지역의 경우 24-32입니다. 20과 같은 상수를 사용할 수 있습니다.)
이 방법을 사용하면 각 사진의 개별 순위를 서로 다른 사진에 유지하는 것보다 메모리 사용량이 훨씬 적은 각 사진에 대해 하나의 숫자 만 유지하면됩니다.
편집 : 의견에 따라 고기를 조금 더 추가했습니다.
문제에 대한 대부분의 순진한 접근 방식에는 몇 가지 심각한 문제가 있습니다. 최악의 경우는 bash.org 및 qdb.us 가 따옴표를 표시 하는 방법입니다. 사용자는 따옴표를 위로 (+1) 또는 아래로 (-1) 투표 할 수 있으며 최고 따옴표 목록은 총 순 점수를 기준으로 정렬됩니다. 이것은 끔찍한 시간 편견으로 고통받습니다. 오래된 인용문은 약간 유머러스하더라도 단순한 수명을 통해 엄청난 수의 긍정적 인 투표를 축적했습니다. 이 알고리즘은 농담이 나이가 들어감에 따라 더 재미있어졌지만-저를 믿으십시오-그렇지 않다면 의미가있을 수 있습니다.
이 문제를 해결하기위한 다양한 시도가 있습니다. 기간 당 긍정적 인 투표 수를보고, 최근 투표에 가중치를 부여하고, 오래된 투표에 대한 감쇄 시스템을 구현하고, 긍정적 인 투표와 부정적 투표의 비율을 계산하는 등 대부분의 다른 결함이 있습니다.
가장 좋은 해결책은 웹 사이트 The Funniest The Cutest , The Fairest , Best Thing에서 사용하는 수정 된 Condorcet 투표 시스템입니다 .
시스템은 직면 한 것들 중 보통이기는 비율을 기준으로 각각에 숫자를 부여합니다. 따라서 각각은 백분율 점수 NumberOfThingsIBeat / (NumberOfThingsIBeat + NumberOfThingsThatBeatMe)를 얻습니다. 또한 세트의 합리적인 비율과 비교 될 때까지 항목이 최상위 목록에서 제외됩니다.
세트에 Condorcet 우승자가있는 경우이 방법으로 찾을 수 있습니다. 통계적 특성을 감안할 때 그럴 가능성이 낮기 때문에 Condorcet 승자가되는 데 "가장 가까운"사람을 찾습니다.
이러한 시스템 구현에 대한 자세한 내용은 랭킹 페어 의 Wikipedia 페이지 가 도움이 될 것입니다.
알고리즘은 사람들이 두 개체를 비교하도록 요구하지만 (Pick-A-or-B 옵션) 솔직히 그것은 좋은 것입니다. 인간이 추상적 인 순위에있는 것보다 두 대상을 비교하는 데 훨씬 더 뛰어나다는 것이 의사 결정 이론에서 매우 잘 받아 들여지고 있다고 생각합니다. 수백만 년의 진화를 통해 우리는 나무에서 가장 좋은 사과를 고르는 데 능숙 해지지 만, 우리가 고른 사과가 진정한 플라톤 형태의 사과에 얼마나 가깝게 쪼개는지 결정하는 것은 끔찍합니다. (이것이 분석 계층 프로세스 가 그토록 멋진 이유입니다 ...하지만 주제에서 약간 벗어난 것입니다.)
마지막으로해야 할 점은 SO가 bash.org 의 알고리즘 과 매우 유사한 최상의 답변 을 찾기 위해 알고리즘을 사용하여 최상의 견적을 찾는 것입니다. 여기에서는 잘 작동하지만 끔찍하게 실패합니다. 왜냐하면 오래되고 높은 등급을 받았지만 지금은 구식 답변이 편집 될 가능성이 높기 때문입니다. bash.org는 편집을 허용하지 않으며, 가능하더라도 지금까지 사용 된 인터넷 밈에 대한 10 년 된 농담을 편집하는 방법도 명확하지 않습니다. 문제의 세부 사항에 따라 다릅니다. :-)
이 질문이 꽤 오래되었다는 것을 알고 있지만 기여할 것이라고 생각했습니다.
I'd look at the TrueSkill system developed at Microsoft Research. It's like ELO but has a much faster convergence time (looks exponential compared to linear), so you get more out of each vote. It is, however, more complex mathematically.
http://en.wikipedia.org/wiki/TrueSkill
I don't like the Hot-or-Not style. Different people would pick different numbers even if they all liked the image exactly the same. Also I hate rating things out of 10, I never know which number to choose.
Pick A-or-B is much simpler and funner. You get to see two images, and comparisons are made between the images on the site.
These equations from Wikipedia makes it simpler/more effective to calculate Elo ratings, the algorithm for images A and B would be simple:
- Get Ne, mA, mB and ratings RA,RB from your database.
- Calculate KA ,KB, QA, QB by using the number of comparisons performed (Ne) and the number of times that image was compared (m) and current ratings :


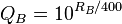
- Calculate EA and EB.


- Score the winner's S : the winner as 1, loser as 0, and if you have a draw as 0.5,
Calculate the new ratings for both using:
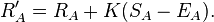
Update the new ratings RA,RB and counts mA,mB in the database.
You may want to go with a combination.
First phase: Hot-or-not style (although I would go with a 3 option vote: Sucks, Meh/OK. Cool!)
Once you've sorted the set into the 3 buckets, then I would select two images from the same bucket and go with the "Which is nicer"
You could then use an English Soccer system of promotion and demotion to move the top few "Sucks" into the Meh/OK region, in order to refine the edge cases.
Ranking 1-10 won't work, everyone has different levels. Someone who always gives 3-7 ratings would have his rankings eclipsed by people who always give 1 or 10.
a-or-b is more workable.
Wow, I'm late in the game.
I like the ELO system very much so, but like Owen says it seems to me that you'd be slow building up any significant results.
I believe humans have much greater capacity than just comparing two images, but you want to keep interactions to the bare minimum.
So how about you show n images (n being any number you can visibly display on a screen, this may be 10, 20, 30 depending on user's preference maybe) and get them to pick which they think is best in that lot. Now back to ELO. You need to modify you ratings system, but keep the same spirit. You have in fact compared one image to n-1 others. So you do your ELO rating n-1 times, but you should divide the change of rating by n-1 to match (so that results with different values of n are coherent with one another).
You're done. You've now got the best of all worlds. A simple rating system working with many images in one click.
If you prefer using the Pick A or B strategy I would recommend this paper: http://research.microsoft.com/en-us/um/people/horvitz/crowd_pairwise.pdf
Chen, X., Bennett, P. N., Collins-Thompson, K., & Horvitz, E. (2013, February). Pairwise ranking aggregation in a crowdsourced setting. In Proceedings of the sixth ACM international conference on Web search and data mining (pp. 193-202). ACM.
The paper tells about the Crowd-BT model which extends the famous Bradley-Terry pairwise comparison model into crowdsource setting. It also gives an adaptive learning algorithm to enhance the time and space efficiency of the model. You can find a Matlab implementation of the algorithm on Github (but I'm not sure if it works).
The defunct web site whatsbetter.com used an Elo style method. You can read about the method in their FAQ on the Internet Archive.
Pick A-or-B its the simplest and less prone to bias, however at each human interaction it gives you substantially less information. I think because of the bias reduction, Pick is superior and in the limit it provides you with the same information.
A very simple scoring scheme is to have a count for each picture. When someone gives a positive comparison increment the count, when someone gives a negative comparison, decrement the count.
Sorting a 1-million integer list is very quick and will take less than a second on a modern computer.
That said, the problem is rather ill-posed - It will take you 50 days to show each image only once.
I bet though you are more interested in the most highly ranked images? So, you probably want to bias your image retrieval by predicted rank - so you are more likely to show images that have already achieved a few positive comparisons. This way you will more quickly just start showing 'interesting' images.
I like the quick-sort option but I'd make a few tweeks:
- Keep the "comparison" results in a DB and then average them.
- Get more than one comparison per view by giving the user 4-6 images and having them sort them.
- Select what images to display by running qsort and recording and trimming anything that you don't have enough data on. Then when you have enough items recorded, spit out a page.
The other fun option would be to use the crowd to teach a neural-net.
참고URL : https://stackoverflow.com/questions/164831/how-to-rank-a-million-images-with-a-crowdsourced-sort
'program story' 카테고리의 다른 글
| 머티리얼 아이콘을 오프라인으로 호스팅하는 방법은 무엇입니까? (0) | 2020.09.21 |
|---|---|
| Excel CSV-숫자 셀 형식 (0) | 2020.09.21 |
| UIView 클래스에서 addSubview와 insertSubview의 차이점 (0) | 2020.09.21 |
| 무엇을 선택해야합니까 : GTK + 또는 Qt? (0) | 2020.09.21 |
| 소프트 키보드가 표시 될 때 레이아웃을 위로 이동하는 방법 android (0) | 2020.09.21 |